Valo Reader for macOS 技术概要

摘要
本文主要介绍了 Valo Reader for macOS(下文简称为“本程序”)的项目布局,工程架构,运行时功能模块与技术细节。你还可以在本文档的其他页面了解本程序的开发动机,使用方式,隐私与安全等内容
什么是 Valo Reader?
Valo Reader 这个项目是我个人在日常生活中逐渐萌生,演化和实施的想法。是我为了在自己电子设备设备上能轻松阅读英文内容,并渐近式地提高自己的英文水平,而自行设计和研发的一款产品,其核心功能展示如下:

当你在使用本程序时,将鼠标移动至你感到生疏的英语单词上。按下指定的按键(默认为 Fn),本程序即会在鼠标指针所在的位置展示对应单词的释义,同时使用语音合成来发音。
目前,你可以通过 Mac App Store 或其他方式来获取本程序
项目布局
下图展示了本项目的主体结构:
本文位于上图中的浅黄色部分,由 docusaurus 生成
本项目的想法最早实现于在浏览器中运行的 js 脚本,你可以在 github 上看到本项目在浏览器上的早期实现及对应的功能展示,即图中浅绿色部分
而本文主要说明了上图中 macOS(浅蓝色部分)的运行方式与技术细节
工程架构
本程序由 flutter create XXX --platform macos 命令创建,其源代码主要分为两部分
flutter 侧
这部分由 dart 编写,可分为三部分
主程序
该部分的主要功能有:
- 通过 method channel �实现 flutter 与 native 的交互
- 渲染用户设置面板(Dashboard)
- 渲染释义展示面板(HUD)与诊断检查信息
- 使用第三方依赖提供的功能
flutter package: 文本块表征
这部分是本程序的核心代码,在 macOS / iOS / Android 三端共享部分逻辑与 UI,其主要功能由有:
- 解析用户设备屏幕上识别到的文本块,结构化文本块,并将其维护到本程序的内存中
- 声明并实现用户视觉焦点与已知的文本信息的交互
- 渲染释义展示面板(HUD)
flutter package: 基础库
在我的所有 flutter 项目中共享的基础依赖
native 侧
这部分由 swift 编写,可分为三部分
主程序部分
持有 flutter engine,通过 method channel 打通 flutter 与 Base、OCR 以及应用程序本身的双向调用
创建项目时默认的 FlutterViewController 已被删除
CocoaPods dependency: Cocoa 功能库
与 Cocoa framework 交互,如:权限申请,键盘监听,鼠标监听,截取屏幕,移动承载 flutter 的 NSWindow以及提供基本若干原生能力
该部分使用 CocoaPods 创建,我也会在该依赖中学习,尝试和实现 Cocoa/AppKit 独有的 API 与功能
CocoaPods dependency: OCR 功能库
与 Apple Vision framework - Text Recognizing 交互,并实现部分逻辑,如:发起文本识别请求,维护文本识别响应缓存
该部分使用 CocoaPods 创建,在 macOS 和 iOS 项目同时依赖并共享代码
运行时功能模块
在运行时,本程序主要可分为用户设置面板 (Dashboard)、释义展示面板 (HUD) 和原生侧 (native) 三个模块
下图展示了本程序在运行时的主要模块及其通讯:


释义展示面板 (HUD)
HUD 是一个的 NSPanel(NSWindow 的子类)实例,其内部承载了一个 FlutterViewController,并绑定了自己的 FlutterEngine 和 FlutterMethodChannel
HUD 的主要任务包含:
- 通过
FlutterMethodChannel向 native 派发 ocr 请求 - 解析 native 对屏幕指定区域的 ocr 结果,并在内存中维护该结果供后继程序逻辑使用
- 监听鼠标位置以在需要时计算释义展示的位置
- 监听键盘按键状态,在变化时派发 ocr 请求并展示单词释义
- 实时同步 Dashboard engine 传递过来的用户设置,并修改展示逻辑
下图展示了该模块所维护的数据映射到屏幕上时的可视化效果:

在 HUD 中的状态
本程序使用 riverpod 管理绝大部分的状态。在构筑本程序时,我的思考过程主要基于状态与状态变化,从展示释义键点击到渲染释义面板动画
在大量使用 riverpod 中的 Provider / StateProvider / ProviderContainer.listen 后,我可以构建一个高度异步,调用顺序不敏感,状态变化驱动的应用程序。在编码过程中,这种方式让程序员可以从一大串的命令式(Imperative)方法调用中解放出来,仅仅需要关注和确保每个最小逻辑单元——Provider,确保其实现是正确的即可,这减少了构建复杂和长串逻辑出错的可能
下面的两张图表展示了本程序的主要功能流程
切换展示释义流程:
用户关注文本块变更流程:
用户设置面板 (Dashboard)
Dashboard 是一个 NSWindow 实例,其内部承载了一个 FlutterViewController,并绑定了不同于 HUD 的独立 engine 与 method channel
Dashboard 的主要任务是为用户提供控制本程序的 UI,包括快捷键设置,开机自启,关于本程序等常见用户交互
同时,Dashboard 会维护本程序在内存和硬盘中的状态,并将这个状态通过 method channel 同步至下面即将要讲到的释义展示面板
原生侧 (native)
原生侧是由 flutter create 命令创建出来的传统 Xcode 工程
在原生侧,我主要关注的问题如下:
- 处理来自
FlutterMethodChannel的调用,并在需要时通过FlutterResult响应对应的 flutter engine - 维护承载 HUD 和 Dashboard 的两个
NSWindow,尤其是当用户的设备同时链接多个屏幕时,正确地设置 HUD 的位置 - 封装并向 flutter 提供能力,如:
- 监听鼠标位置变化和键盘状态变化,并将状态同步至 flutter
- 为 flutter 提供 OCR 和语音合成能力
- 在执行 OCR 时使用 swift 实现必要的性能优化
技术细节
得益于 Apple 一脉相承的 API 设计以及同样的编程语言,熟练于 iOS 应用开发(Cocoa Touch & UIKit)的程序员在面对与 macOS 交互的 Cocoa 和 AppKit 框架时,可以复用很多思想与逻辑
但相比于 iOS,macOS 给了用户更大的舞台,也让开发者面对了更多的挑战: 鼠标,键盘,窗口和屏幕
在开发本程序的过程中,我遇到了诸多的困难,也在茅塞顿开时收获了很多快乐,我在这一章节会记录一下
多屏幕
macOS 及其运行的硬件设备常常连接着多块屏幕,本程序的核心功能就是在任意的屏幕位置展示单词释义,这就要确保:
- 将释义展示面板(HUD)放置于正确的位置上
- flutter 在请求 native 捕捉屏幕时,捕捉的矩形框的位置正确
- flutter 在解析 ocr response 后,结果可以正确地和屏幕上真正的内容建立映射
和 UIKit 中常用的 CGRect 不同,AppKit 对设备屏幕的抽象 NSScreen,其坐标以 NSRect 计算,坐标系原点为 macOS 原始屏幕的左下角。而此时,如果你给你的设备连接上了其他的屏幕,NSScreen.screens 所呈现屏幕布局,可能就会变成下图所示的样子:
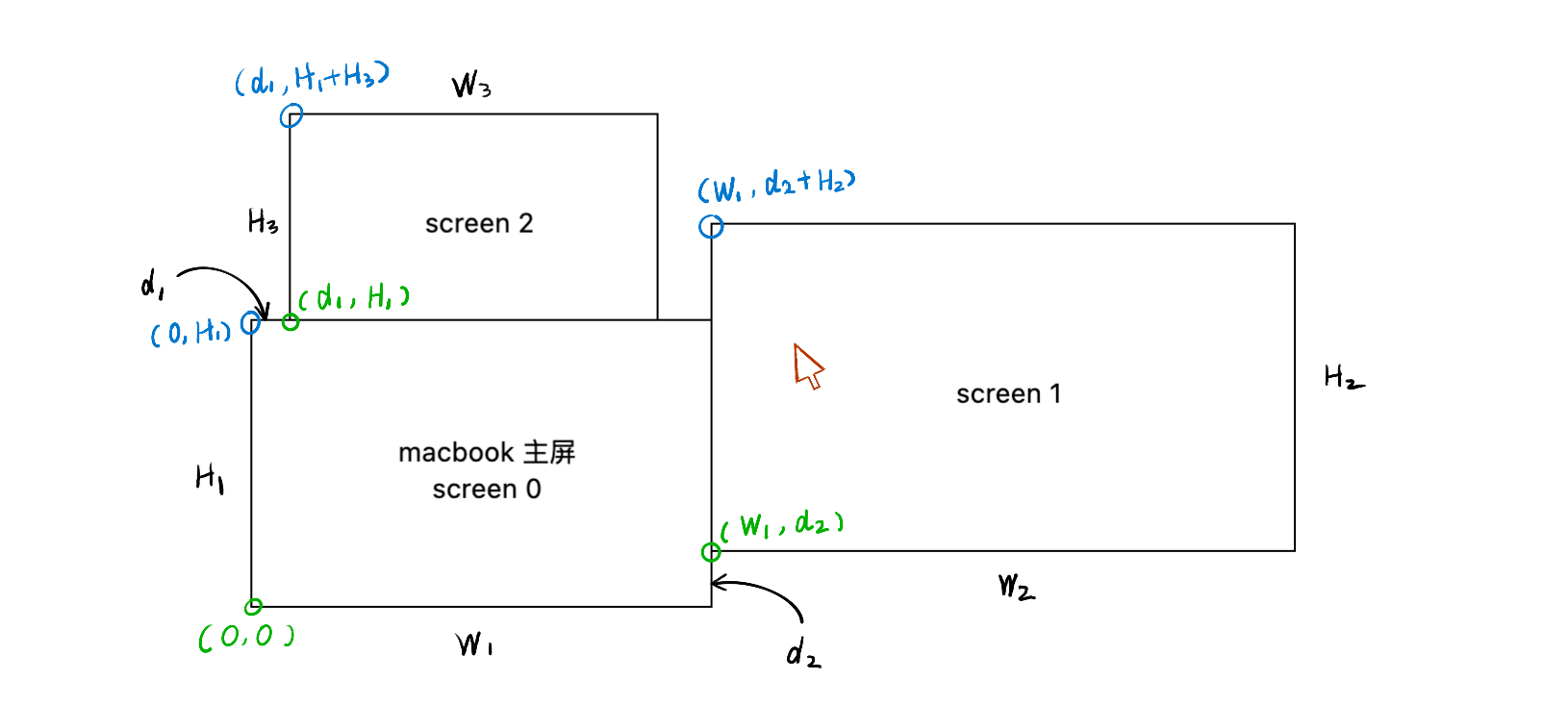
screen 1 的左下角坐标值并非是 (0, 0),而是 screen 1 和 screen 0 的 (0, 0) 点的相对位置 (w1, d2)。通过监听鼠标移动事件获取的鼠标位置 event.locationInWindow,也是相对于原点的 NSPoint
在开发时,仅仅将自己的思维从 iOS 的 CGRect 坐标系转化至 NSRect 坐标系还算简单。但在后继的逻辑中,因为 OCR 结果的 VNRectangleObservation.boundingBox 又会回到 CGRect 坐标系,坐标系的频繁转化确实会给人带来一定的困扰
屏幕捕捉
想捕捉 macOS 的屏幕,你可以调用 CGDisplayCreateImage 函数
但值得注意的是,想要截取屏幕上其他进程的内容(比如 IDE 或者浏览器),需要预先通过 CGRequestScreenCaptureAccess,申请到截取其他进程 UI 的权限,否则 CGDisplayCreateImage 只能拿到 macOS 的桌面(以及程序本身)
OCR
本程序使用 Apple 为开发者提供的 Vision - Recognizing Text 进行屏幕文本的提取
OCR 请求的调用由 flutter side 唤起:
void dispatchOCRRequestToNative() async {
final x = 100;
final y = 100;
final width = 300;
final height = 80;
final dimensions = [x, y, width, height];
final result = await methodChannel.invokeMethod("captureAndOCR", dimensions);
// parse the result from native
// ...
}
Native side 在接收到请求后,会执行截屏和识别操作:
import Vision
// ...
let result : FlutterResult = ...
let image = captureScreen()
let handler = VNImageRequestHandler(cgImage: image)
let request = VNRecognizeTextRequest { request, error in
// ocr finished
let parsedResult = parse(request.results)
result(parsedResult)
}
handler.perform([request])
性能表现
在 macbook 2021 的 m1 pro 上,以 320✕75 的设计分辨率截图(实际分辨率为 640✕150),每秒 11 帧的情况下进行长时间的截图和 OCR 操作,整个流程�的延迟平均约为 65ms,我认为还算是一个可接受的状态
节能优化
即便是性能允许,优化也是应该做的,用户一旦使用你的 App,就感觉 macbook 的 C 面发热,这是无法容忍的
当前在 OCR 流程中主要的性能优化步骤是在 native 维护一个先进先出,最大容量为 40 帧的字典,以图片数据为 key 缓存 OCR 的结果,下面是简化后的代码:
let cacheManager = CacheManager<CFData, Result>()
// ...
let image = captureScreen()
let key = image.dataProvider.data
if let cachedResult = cacheManager[key] {
delegate.onOCRResult(cachedResult)
return
}
// ...
dispatchOCRRequestToDeviceGPU(image) { result
cacheManager[key] = result
// ... other logic
}
// ...
当鼠标指针位置不变,截图获取的图片不变时,native 在处理 OCR 请求时会先命中缓存,并直接返回结果,以减少非必需的 GPU 调用
在系统自带的活动监视器中查看进程。发现,在应用的缓存策略后,在本程序活动时,其 CPU/GPU 占用率确实降低了很多,同时,OCR 的缓存结果被降为了 5ms
我感觉,以 CFData 作为 key 查询字典还不是效率最高的算法,应该可以继续探索一下
不截取自己
在我进行开发时,发现当本程序在展示单词释义 UI (HUD)时,因为 HUD 本身也会在一定范围内被截屏函数捕获,导致 HUD 会影响 OCR 的结果,而在 OCR 结果变动后,HUD 又会随之发生变动,再次影响 OCR 结果,就这样循环往复,连缓存也都失效了。在查阅和尝试大量的 API 后,我终于在 NSWindow 中找到了 sharingType 这个属性,屏幕捕捉方法捕获 HUD 自身,总算是打破了这个链条
结果解析,分词与定位
对 Vision - VNRecognizeTextRequest 的结果解析是个复杂的任务
执行这个复杂任务的原因有三:
- 本程序设计的交互是“用户将鼠标移动至感兴趣的单词上时展示单词释义”,这就要求我们知道屏幕上每个单词的具体位置和内容
- 本程序针对源代码特化,在面对驼峰命名法时,需要知道构成一个 symbol 的每个单词的意思:
ThisIsAVeryVeryLongClassName->This,IsAVery,Very,Long,Class,Name(因过于简单,丢弃长度小于 3 的英语单词) - 我们要以单词的文本内容为 key,查询数据库。在文本序列包含特殊字符时,我们是无法从数据库中查到单词释义的。所以要移除非字母字符。同时,这一操作也可以自然而然地适配编程语言中的其他命名方式,比如移除下划线就可以适应蛇形命名法
假设我们在对下面的图片执行 OCR 请求

在 Native 端取 VNRecognizeTextRequest.results.topCandidates(1) 后,结果如下
[
// 同时包含 rect 信息
"Vision provides its text-recognition capabilities through VNRecognizeText",
// 同时包含 rect 信息
"Request, an image-based request type that finds and extracts text in images. The",
// 同时包含 rect 信息
"following example shows how to use VNImageRequestHandler to perform a",
// 同时包含 rect 信息
"VNRecognizeTextRequest for recognizing text in the specified CGImage.",
]
在 Native 端�以空格字符和 VNRecognizedText.boundingBox(for:) 对 OCR 结果进行第一次整理,上述的结果会变为这样:
[
// 同时包含 rect 信息
"Vision", "provides", "its", "text-recognition", "capabilities", "through", "VNRecognizeText",
// 同时包含 rect 信息
"Request,", "an", "image-based", "request", "type", "that", "finds", "and", "extracts", "text", "in", "images.", "The",
// 同时包含 rect 信息
"following", "example", "shows", "how", "to", "use", "VNImageRequestHandler", "to", "perform", "a",
// 同时包含 rect 信息
"VNRecognizeTextRequest", "for", "recognizing", "text", "in", "the", "specified", "CGImage.",
]
最后将 boundingBox 的返回值和截屏尺寸进行乘算,返回给 flutter 端。Flutter 端在拿到结果后主要进行两个步骤:
- 将文本视为等宽字体,移除非英文字符,计算新的 rect
- 将文本视为等宽字体,对包含大写字母的字符串进行分割,计算新的 rect
这样,文本块的内容在 flutter 端就会变成这样:
[
// 同时包含 rect 信息
"Vision", "provides", "its", "text", "recognition", "capabilities", "through", "Recognize", "Text",
// 同时包含 rect 信息
"Request","image", "based", "request", "type", "that", "finds", "and", "extracts", "text", "images", "The",
// 同时包含 rect 信息
"following", "example", "shows", "how", "use", "Image", "Request", "Handler", "perform",
// 同时包含 rect 信息
"Recognize", "Text", "Request", "for", "recognizing", "text", "the", "specified", "Image",
]
最后,flutter 侧会以下面的代码对这些 OCR 信息进行抽象:
/// The representation of block
///
/// 文本块表征
class Block {
String text;
double x;
double y;
double w;
double h;
}
// ...
/// All text representations in memory
///
/// 所有文本块表征
final blocks = StateProvider<List<Block>>((_) => []);
上面的数据在屏幕上的可视化效果如下:

其中外围绿框代表截屏范围,内部的小绿框代表 native 端返回的结果,小绿框内部的蓝色框代表 flutter side 第二次解析结果。可以看到,"VNImageRequestHandler" 这个字符串被分割为了 "Image", "Request", "Handler" 这三个文本块。这样,我就可以知道用户到底对哪一段字母序列(单词)感兴趣了(假设源代码符号的命名是规范的 😇)。
你也可以打开本程序的用户设置面板来直接观察其运行时表现:

多引擎与状态同步
本程序在运行时会创建两个 flutter engine,分别用于渲染"释义展示面板(HUD)"和"欢迎与设置页面(Dashboard)"
这两个引擎均通过基本方式创建,均采用 FlutterMethodChannel 与 native 进行通讯
双引擎共享同一份代码,经由不同的 dart 入口函数启动:
// 设置页面 (Dashboard)
dashboardEngine = FlutterEngine(name: "dashboard", project: nil)
dashboardChannel = FlutterMethodChannel(name: "dashboard", binaryMessenger: dashboardEngine.binaryMessenger)
dashboardEngine.run(withEntrypoint: "_dashboard")
//...
// 释义展示面板 (HUD)
hudEngine = FlutterEngine(name: "hud", project: nil)
hudChannel = FlutterMethodChannel(name: "hud", binaryMessenger: hudEngine.binaryMessenger)
hudChannel.run(withEntrypoint: "_hud")
我个人没有使用官方提供的 FlutterEngineGroup 方案,因为在当初进行尝试时发现了引擎无响应的问题,至今仍然是 P2 级别的 open issue
跨引擎状态同步
本程序使用 riverpod 来管理绝大部分状态,所以在同步状态时,我也期望自己的自己的心智模型可以更贴近 riverpod
在运行时,Dashboard engine 需要将用户设置同步至 HUD engine (比如更改查词快捷键),我在这里监听了 Dashboard engine 对应的 StateProvider 的变更,并通过 method channel,经由 native 转发至 HUD engine,HUD engine 在收到了通知后,再更新自己维护的 StateProvider。从而实现了跨引擎的状态同步
释义查询
本程序在查询单词释义时使用本地 sqlite 数据库,数据库源于 ecdict-ultimate
鉴于开源数据库过于巨大,且存在一些本程序无需使用的 columns,我又使用 dart 和 drift 对其进行了清洗和剪裁
在查询时,本程序会将查询的本文串“打散”,并一齐请求数据库,以期能命中不断千变万化的英语单词:
final sequence = "qwertyuiopasdfghjkl";
final sequences = ["qwe","wer","ert",...,"qwer","wert",...,"qwert",...,"qwertyuiopasdfghjkl"];
final List<QueryResult> results = await queryDB(keys:sequences); // average latency: ~6ms
在请求完成后,本程序会对请求结果进行去重,逻辑如下:
- 结果中包含 owl (猫头鹰)
- 结果中包含 knowledge(知识)
- 序列 "knowledge" 包含 "owl",移除查询结果中的 owl
目前,该逻辑还没有实现对冲突的判定:如向数据库查询的 key 为 "gitignore",查询结果为 ["git", "tig", "ignore"],目前这三个结果都会被渲染到 HUD 上。但显然,选取 git 和 ignore 这两个查询结果造成的 “冲突” 是最小的
发音
本程序使用 AVFoundation - Speech synthesis API 来实时合成语音
该 API 可以同时在 iOS/macOS 上使用,且发音较为准确,以我自身的能力(全国大学英语四级)来看,效果还算满意,确实比我的发音准 🤣
当然,后继如果有更高的需求,也有很多其他可选方案